![]()
![]()
In [ ]:
Copied!
%%capture --no-stderr
%pip install --quiet -U langchain_core langgraph langchain_openai
%%capture --no-stderr
%pip install --quiet -U langchain_core langgraph langchain_openai
In [1]:
Copied!
import os, getpass
def _set_env(var: str):
if not os.environ.get(var):
os.environ[var] = getpass.getpass(f"{var}: ")
_set_env("OPENAI_API_KEY")
import os, getpass
def _set_env(var: str):
if not os.environ.get(var):
os.environ[var] = getpass.getpass(f"{var}: ")
_set_env("OPENAI_API_KEY")
In [2]:
Copied!
_set_env("LANGSMITH_API_KEY")
os.environ["LANGSMITH_TRACING"] = "true"
os.environ["LANGSMITH_PROJECT"] = "langchain-academy"
_set_env("LANGSMITH_API_KEY")
os.environ["LANGSMITH_TRACING"] = "true"
os.environ["LANGSMITH_PROJECT"] = "langchain-academy"
In [3]:
Copied!
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o",temperature=0)
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o",temperature=0)
我们将继续使用 MessagesState,如前所述。
除了内置的 messages 键之外,我们现在还将包含一个自定义键(summary)。
In [5]:
Copied!
from langgraph.graph import MessagesState
class State(MessagesState):
summary: str
from langgraph.graph import MessagesState
class State(MessagesState):
summary: str
我们将定义一个节点来调用我们的LLM(大语言模型),该节点会在提示词中整合摘要信息(如果存在摘要的话)。
In [7]:
Copied!
from langchain_core.messages import SystemMessage, HumanMessage, RemoveMessage
# Define the logic to call the model
def call_model(state: State):
# Get summary if it exists
summary = state.get("summary", "")
# If there is summary, then we add it
if summary:
# Add summary to system message
system_message = f"Summary of conversation earlier: {summary}"
# Append summary to any newer messages
messages = [SystemMessage(content=system_message)] + state["messages"]
else:
messages = state["messages"]
response = model.invoke(messages)
return {"messages": response}
from langchain_core.messages import SystemMessage, HumanMessage, RemoveMessage
# Define the logic to call the model
def call_model(state: State):
# Get summary if it exists
summary = state.get("summary", "")
# If there is summary, then we add it
if summary:
# Add summary to system message
system_message = f"Summary of conversation earlier: {summary}"
# Append summary to any newer messages
messages = [SystemMessage(content=system_message)] + state["messages"]
else:
messages = state["messages"]
response = model.invoke(messages)
return {"messages": response}
我们将定义一个节点来生成摘要。
注意,这里我们会使用 RemoveMessage 在生成摘要后对状态进行过滤。
In [9]:
Copied!
def summarize_conversation(state: State):
# First, we get any existing summary
summary = state.get("summary", "")
# Create our summarization prompt
if summary:
# A summary already exists
summary_message = (
f"This is summary of the conversation to date: {summary}\n\n"
"Extend the summary by taking into account the new messages above:"
)
else:
summary_message = "Create a summary of the conversation above:"
# Add prompt to our history
messages = state["messages"] + [HumanMessage(content=summary_message)]
response = model.invoke(messages)
# Delete all but the 2 most recent messages
delete_messages = [RemoveMessage(id=m.id) for m in state["messages"][:-2]]
return {"summary": response.content, "messages": delete_messages}
def summarize_conversation(state: State):
# First, we get any existing summary
summary = state.get("summary", "")
# Create our summarization prompt
if summary:
# A summary already exists
summary_message = (
f"This is summary of the conversation to date: {summary}\n\n"
"Extend the summary by taking into account the new messages above:"
)
else:
summary_message = "Create a summary of the conversation above:"
# Add prompt to our history
messages = state["messages"] + [HumanMessage(content=summary_message)]
response = model.invoke(messages)
# Delete all but the 2 most recent messages
delete_messages = [RemoveMessage(id=m.id) for m in state["messages"][:-2]]
return {"summary": response.content, "messages": delete_messages}
我们将添加一个条件分支,根据对话长度来决定是否生成摘要。
In [8]:
Copied!
from langgraph.graph import END
# Determine whether to end or summarize the conversation
def should_continue(state: State):
"""Return the next node to execute."""
messages = state["messages"]
# If there are more than six messages, then we summarize the conversation
if len(messages) > 6:
return "summarize_conversation"
# Otherwise we can just end
return END
from langgraph.graph import END
# Determine whether to end or summarize the conversation
def should_continue(state: State):
"""Return the next node to execute."""
messages = state["messages"]
# If there are more than six messages, then we summarize the conversation
if len(messages) > 6:
return "summarize_conversation"
# Otherwise we can just end
return END
添加记忆功能¶
请记住,状态在单次图执行过程中是临时的。
这限制了我们进行多轮对话(包含中断场景)的能力。
正如模块1末尾介绍的,我们可以使用持久化功能来解决这个问题!
LangGraph可以通过检查点(checkpointer)自动在每一步执行后保存图状态。
这个内置的持久化层为我们提供了记忆功能,使得LangGraph能够从最后一次状态更新处继续执行。
如先前所示,最容易使用的方案之一是MemorySaver——这是一个用于存储图状态的基于内存的键值存储。
我们只需使用检查点来编译图,就能让图具备记忆功能!
In [10]:
Copied!
from IPython.display import Image, display
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph, START
# Define a new graph
workflow = StateGraph(State)
workflow.add_node("conversation", call_model)
workflow.add_node(summarize_conversation)
# Set the entrypoint as conversation
workflow.add_edge(START, "conversation")
workflow.add_conditional_edges("conversation", should_continue)
workflow.add_edge("summarize_conversation", END)
# Compile
memory = MemorySaver()
graph = workflow.compile(checkpointer=memory)
display(Image(graph.get_graph().draw_mermaid_png()))
from IPython.display import Image, display
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph, START
# Define a new graph
workflow = StateGraph(State)
workflow.add_node("conversation", call_model)
workflow.add_node(summarize_conversation)
# Set the entrypoint as conversation
workflow.add_edge(START, "conversation")
workflow.add_conditional_edges("conversation", should_continue)
workflow.add_edge("summarize_conversation", END)
# Compile
memory = MemorySaver()
graph = workflow.compile(checkpointer=memory)
display(Image(graph.get_graph().draw_mermaid_png()))

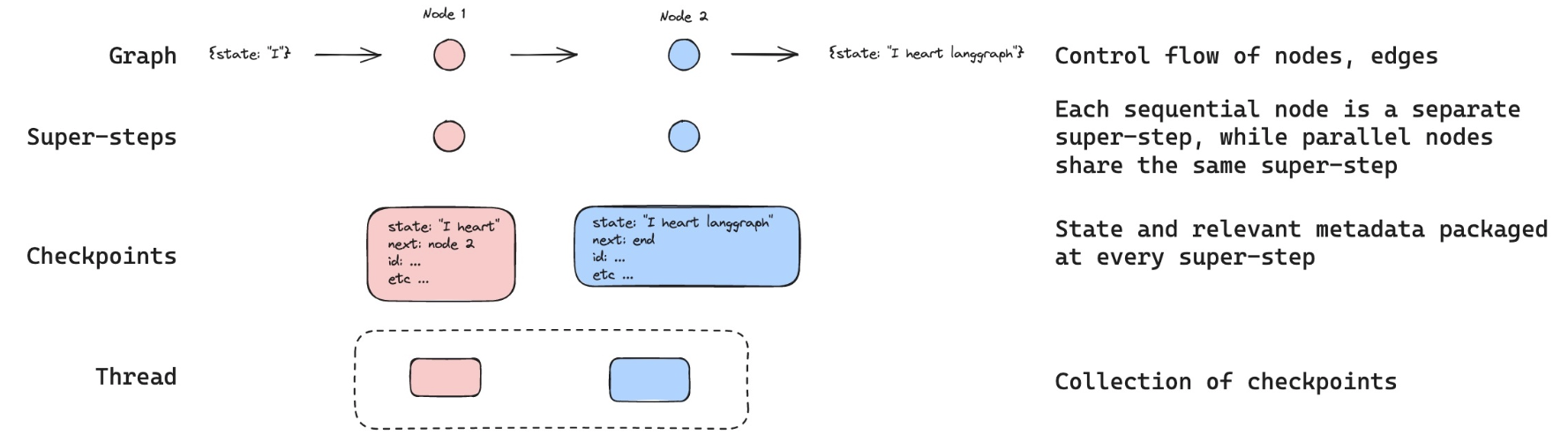
线程¶
检查点保存器会在每个步骤将状态保存为一个检查点。
这些已保存的检查点可以归类为对话的一个thread(线程)。
以Slack为例进行类比:不同的频道承载着不同的对话。
线程就像Slack频道,用于捕获分组的状态集合(例如对话)。
下方我们使用configurable来设置线程ID。
In [11]:
Copied!
# Create a thread
config = {"configurable": {"thread_id": "1"}}
# Start conversation
input_message = HumanMessage(content="hi! I'm Lance")
output = graph.invoke({"messages": [input_message]}, config)
for m in output['messages'][-1:]:
m.pretty_print()
input_message = HumanMessage(content="what's my name?")
output = graph.invoke({"messages": [input_message]}, config)
for m in output['messages'][-1:]:
m.pretty_print()
input_message = HumanMessage(content="i like the 49ers!")
output = graph.invoke({"messages": [input_message]}, config)
for m in output['messages'][-1:]:
m.pretty_print()
# Create a thread
config = {"configurable": {"thread_id": "1"}}
# Start conversation
input_message = HumanMessage(content="hi! I'm Lance")
output = graph.invoke({"messages": [input_message]}, config)
for m in output['messages'][-1:]:
m.pretty_print()
input_message = HumanMessage(content="what's my name?")
output = graph.invoke({"messages": [input_message]}, config)
for m in output['messages'][-1:]:
m.pretty_print()
input_message = HumanMessage(content="i like the 49ers!")
output = graph.invoke({"messages": [input_message]}, config)
for m in output['messages'][-1:]:
m.pretty_print()
================================== Ai Message ================================== Hi Lance! How can I assist you today? ================================== Ai Message ================================== You mentioned that your name is Lance. How can I help you today, Lance? ================================== Ai Message ================================== That's awesome, Lance! The San Francisco 49ers have a rich history and a passionate fan base. Do you have a favorite player or a memorable game that stands out to you?
目前我们尚未生成对话状态的摘要,因为当前消息数量仍 ≤ 6 条。
这个逻辑是在 should_continue 中设置的:
# 如果消息数量超过六条,则对对话进行摘要处理
if len(messages) > 6:
return "summarize_conversation"
由于我们保留了完整的对话线程,因此可以继续该会话。
In [12]:
Copied!
graph.get_state(config).values.get("summary","")
graph.get_state(config).values.get("summary","")
Out[12]:
''
带有线程 ID 的 config 允许我们从先前记录的状态继续执行!
In [13]:
Copied!
input_message = HumanMessage(content="i like Nick Bosa, isn't he the highest paid defensive player?")
output = graph.invoke({"messages": [input_message]}, config)
for m in output['messages'][-1:]:
m.pretty_print()
input_message = HumanMessage(content="i like Nick Bosa, isn't he the highest paid defensive player?")
output = graph.invoke({"messages": [input_message]}, config)
for m in output['messages'][-1:]:
m.pretty_print()
================================== Ai Message ==================================
Yes, Nick Bosa is indeed one of the highest-paid defensive players in the NFL. In September 2023, he signed a record-breaking contract extension with the San Francisco 49ers, making him the highest-paid defensive player at that time. His performance on the field has certainly earned him that recognition. It's great to hear you're a fan of such a talented player!
/var/folders/l9/bpjxdmfx7lvd1fbdjn38y5dh0000gn/T/ipykernel_18661/23381741.py:23: LangChainBetaWarning: The class `RemoveMessage` is in beta. It is actively being worked on, so the API may change. delete_messages = [RemoveMessage(id=m.id) for m in state["messages"][:-2]]
In [14]:
Copied!
graph.get_state(config).values.get("summary","")
graph.get_state(config).values.get("summary","")
Out[14]:
"Lance introduced himself and mentioned that he is a fan of the San Francisco 49ers. He specifically likes Nick Bosa and inquired if Bosa is the highest-paid defensive player. I confirmed that Nick Bosa signed a record-breaking contract extension in September 2023, making him the highest-paid defensive player at that time, and acknowledged Bosa's talent and Lance's enthusiasm for the player."
LangSmith¶
让我们来查看追踪记录吧!