使用属性图存储库¶
在 LlamaIndex 中,通常你会创建一个 PropertyGraphStore,将其传入 PropertyGraphIndex,然后它会自动用于数据插入和查询操作。
但有时你可能需要直接使用图存储库。也许你想自行创建图结构并交给检索器或索引使用,或者希望编写自己的代码来管理和查询图存储库。
本指南将演示如何在不使用索引的情况下,直接对图存储库进行数据填充和查询操作。
环境配置¶
本节我们将使用 Neo4j 作为属性图存储数据库。
要在本地启动 Neo4j,请先确保已安装 Docker。随后可通过以下 Docker 命令启动数据库:
docker run \
-p 7474:7474 -p 7687:7687 \
-v $PWD/data:/data -v $PWD/plugins:/plugins \
--name neo4j-apoc \
-e NEO4J_apoc_export_file_enabled=true \
-e NEO4J_apoc_import_file_enabled=true \
-e NEO4J_apoc_import_file_use__neo4j__config=true \
-e NEO4JLABS_PLUGINS=\[\"apoc\"\] \
neo4j:latest
启动后,可通过 http://localhost:7474/ 访问数据库。首次登录时需使用默认用户名/密码 neo4j 和 neo4j。
初次登录后,系统会要求修改默认密码。
完成上述步骤后,即可开始创建您的第一个属性图!
In [ ]:
Copied!
from llama_index.graph_stores.neo4j import Neo4jPropertyGraphStore
pg_store = Neo4jPropertyGraphStore(
username="neo4j",
password="llamaindex",
url="bolt://localhost:7687",
)
from llama_index.graph_stores.neo4j import Neo4jPropertyGraphStore
pg_store = Neo4jPropertyGraphStore(
username="neo4j",
password="llamaindex",
url="bolt://localhost:7687",
)
插入数据¶
现在我们已经初始化了存储,可以向其中添加内容了!
向属性图存储中插入数据主要包括插入以下节点类型:
EntityNode- 包含带有标签的人物、地点或事物ChunkNode- 包含实体或关系来源的原始文本片段
以及插入Relation关系(即连接多个节点)。
In [ ]:
Copied!
from llama_index.core.graph_stores.types import EntityNode, ChunkNode, Relation
# Create a two entity nodes
entity1 = EntityNode(label="PERSON", name="Logan", properties={"age": 28})
entity2 = EntityNode(label="ORGANIZATION", name="LlamaIndex")
# Create a relation
relation = Relation(
label="WORKS_FOR",
source_id=entity1.id,
target_id=entity2.id,
properties={"since": 2023},
)
from llama_index.core.graph_stores.types import EntityNode, ChunkNode, Relation
# Create a two entity nodes
entity1 = EntityNode(label="PERSON", name="Logan", properties={"age": 28})
entity2 = EntityNode(label="ORGANIZATION", name="LlamaIndex")
# Create a relation
relation = Relation(
label="WORKS_FOR",
source_id=entity1.id,
target_id=entity2.id,
properties={"since": 2023},
)
在定义了一些实体和关系后,我们就可以插入它们了!
In [ ]:
Copied!
pg_store.upsert_nodes([entity1, entity2])
pg_store.upsert_relations([relation])
pg_store.upsert_nodes([entity1, entity2])
pg_store.upsert_relations([relation])
如果我们愿意,也可以定义这些文本块来自何处
In [ ]:
Copied!
from llama_index.core.schema import TextNode
source_node = TextNode(text="Logan (age 28), works for LlamaIndex since 2023.")
relations = [
Relation(
label="MENTIONS",
target_id=entity1.id,
source_id=source_node.node_id,
),
Relation(
label="MENTIONS",
target_id=entity2.id,
source_id=source_node.node_id,
),
]
pg_store.upsert_llama_nodes([source_node])
pg_store.upsert_relations(relations)
from llama_index.core.schema import TextNode
source_node = TextNode(text="Logan (age 28), works for LlamaIndex since 2023.")
relations = [
Relation(
label="MENTIONS",
target_id=entity1.id,
source_id=source_node.node_id,
),
Relation(
label="MENTIONS",
target_id=entity2.id,
source_id=source_node.node_id,
),
]
pg_store.upsert_llama_nodes([source_node])
pg_store.upsert_relations(relations)
现在,你的图应该包含 3 个节点和 3 条关系。
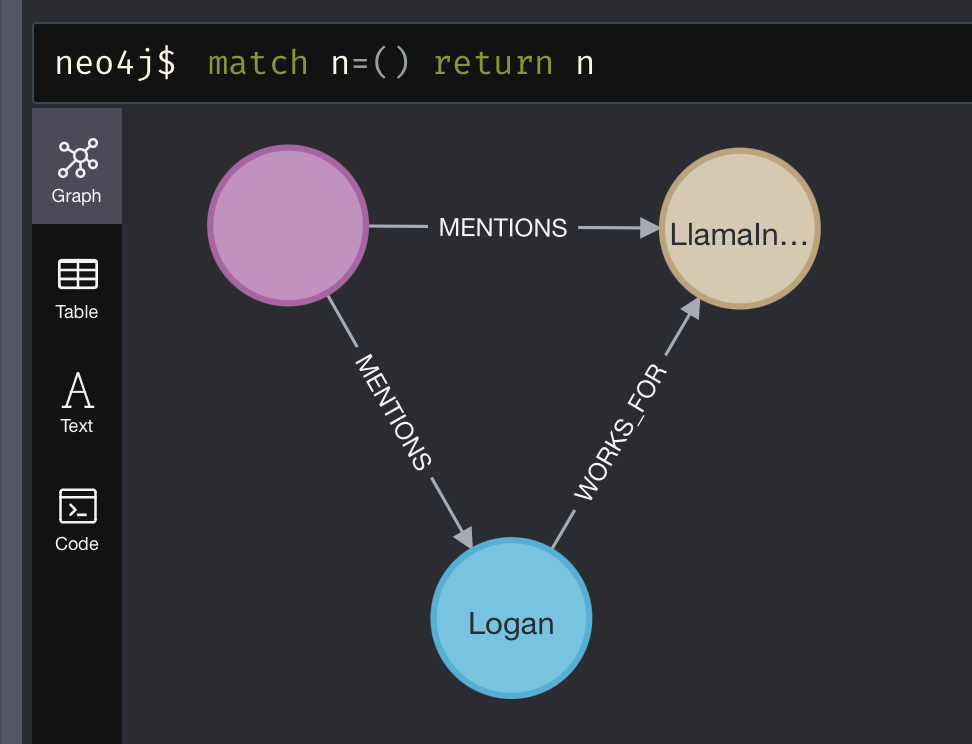
检索¶
现在我们的图数据库中已经填充了一些节点和关系,可以开始使用检索功能了!
In [ ]:
Copied!
# get a node
kg_nodes = pg_store.get(ids=[entity1.id])
print(kg_nodes)
# get a node
kg_nodes = pg_store.get(ids=[entity1.id])
print(kg_nodes)
[EntityNode(label='PERSON', embedding=None, properties={'age': 28, 'name': 'Logan'}, name='Logan')]
In [ ]:
Copied!
# get using properties
kg_nodes = pg_store.get(properties={"age": 28})
print(kg_nodes)
# get using properties
kg_nodes = pg_store.get(properties={"age": 28})
print(kg_nodes)
[EntityNode(label='PERSON', embedding=None, properties={'age': 28, 'name': 'Logan'}, name='Logan')]
In [ ]:
Copied!
# get paths from a node
paths = pg_store.get_rel_map(kg_nodes, depth=1)
for path in paths:
print(f"{path[0].id} -> {path[1].id} -> {path[2].id}")
# get paths from a node
paths = pg_store.get_rel_map(kg_nodes, depth=1)
for path in paths:
print(f"{path[0].id} -> {path[1].id} -> {path[2].id}")
Logan -> WORKS_FOR -> LlamaIndex
In [ ]:
Copied!
# Run a cypher query (this will get all entity nodes)
query = "match (n:`__Entity__`) return n"
result = pg_store.structured_query(query)
print(result)
# Run a cypher query (this will get all entity nodes)
query = "match (n:`__Entity__`) return n"
result = pg_store.structured_query(query)
print(result)
[{'n': {'name': 'Logan', 'id': 'Logan', 'age': 28}}, {'n': {'name': 'LlamaIndex', 'id': 'LlamaIndex'}}]
In [ ]:
Copied!
# get the original text node back
llama_nodes = pg_store.get_llama_nodes([source_node.node_id])
print(llama_nodes[0].text)
# get the original text node back
llama_nodes = pg_store.get_llama_nodes([source_node.node_id])
print(llama_nodes[0].text)
Logan (age 28), works for LlamaIndex since 2023.
In [ ]:
Copied!
new_node = EntityNode(
label="PERSON", name="Logan", properties={"age": 28, "location": "Canada"}
)
pg_store.upsert_nodes([new_node])
new_node = EntityNode(
label="PERSON", name="Logan", properties={"age": 28, "location": "Canada"}
)
pg_store.upsert_nodes([new_node])
In [ ]:
Copied!
nodes = pg_store.get(properties={"age": 28})
print(nodes)
nodes = pg_store.get(properties={"age": 28})
print(nodes)
[EntityNode(label='PERSON', embedding=None, properties={'location': 'Canada', 'age': 28, 'name': 'Logan'}, name='Logan')]
In [ ]:
Copied!
# delete our entities
pg_store.delete(ids=[entity1.id, entity2.id])
# delete our text nodes
pg_store.delete([source_node.node_id])
# delete our entities
pg_store.delete(ids=[entity1.id, entity2.id])
# delete our text nodes
pg_store.delete([source_node.node_id])
In [ ]:
Copied!
nodes = pg_store.get(ids=[entity1.id, entity2.id])
print(nodes)
nodes = pg_store.get(ids=[entity1.id, entity2.id])
print(nodes)
[]