In [ ]:
Copied!
%pip install llama-index
%pip install llama-index
安装¶
In [ ]:
Copied!
import os
os.environ["OPENAI_API_KEY"] = "sk-proj-..."
import os
os.environ["OPENAI_API_KEY"] = "sk-proj-..."
In [ ]:
Copied!
!mkdir -p 'data/paul_graham/'
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/paul_graham/paul_graham_essay.txt' -O 'data/paul_graham/paul_graham_essay.txt'
!mkdir -p 'data/paul_graham/'
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/paul_graham/paul_graham_essay.txt' -O 'data/paul_graham/paul_graham_essay.txt'
In [ ]:
Copied!
import nest_asyncio
nest_asyncio.apply()
import nest_asyncio
nest_asyncio.apply()
In [ ]:
Copied!
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data/paul_graham/").load_data()
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data/paul_graham/").load_data()
构建¶
In [ ]:
Copied!
from llama_index.core import PropertyGraphIndex
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
index = PropertyGraphIndex.from_documents(
documents,
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.3),
embed_model=OpenAIEmbedding(model_name="text-embedding-3-small"),
show_progress=True,
)
from llama_index.core import PropertyGraphIndex
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
index = PropertyGraphIndex.from_documents(
documents,
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.3),
embed_model=OpenAIEmbedding(model_name="text-embedding-3-small"),
show_progress=True,
)
/Users/loganmarkewich/Library/Caches/pypoetry/virtualenvs/llama-index-bXUwlEfH-py3.11/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html from .autonotebook import tqdm as notebook_tqdm Parsing nodes: 100%|██████████| 1/1 [00:00<00:00, 25.46it/s] Extracting paths from text: 100%|██████████| 22/22 [00:12<00:00, 1.72it/s] Extracting implicit paths: 100%|██████████| 22/22 [00:00<00:00, 36186.15it/s] Generating embeddings: 100%|██████████| 1/1 [00:00<00:00, 1.14it/s] Generating embeddings: 100%|██████████| 5/5 [00:00<00:00, 5.43it/s]
让我们回顾一下刚才发生的具体过程:
PropertyGraphIndex.from_documents()- 我们将文档加载到索引中Parsing nodes- 索引将文档解析为节点Extracting paths from text- 节点被传递给LLM,并提示LLM生成知识图谱三元组(即路径)Extracting implicit paths- 每个node.relationships属性被用来推断隐式路径Generating embeddings- 为每个文本节点和图节点生成嵌入向量(因此该过程会执行两次)
让我们探索所创建的内容!出于调试目的,默认的 SimplePropertyGraphStore 包含一个辅助功能,可将图的 networkx 表示形式保存为 html 文件。
In [ ]:
Copied!
index.property_graph_store.save_networkx_graph(name="./kg.html")
index.property_graph_store.save_networkx_graph(name="./kg.html")
在浏览器中打开 html 文件,我们就能看到生成的图谱!
如果放大观察,每个带有大量连接的"密集"节点实际上是源文本块,提取出的实体和关系会从这里分叉延伸。
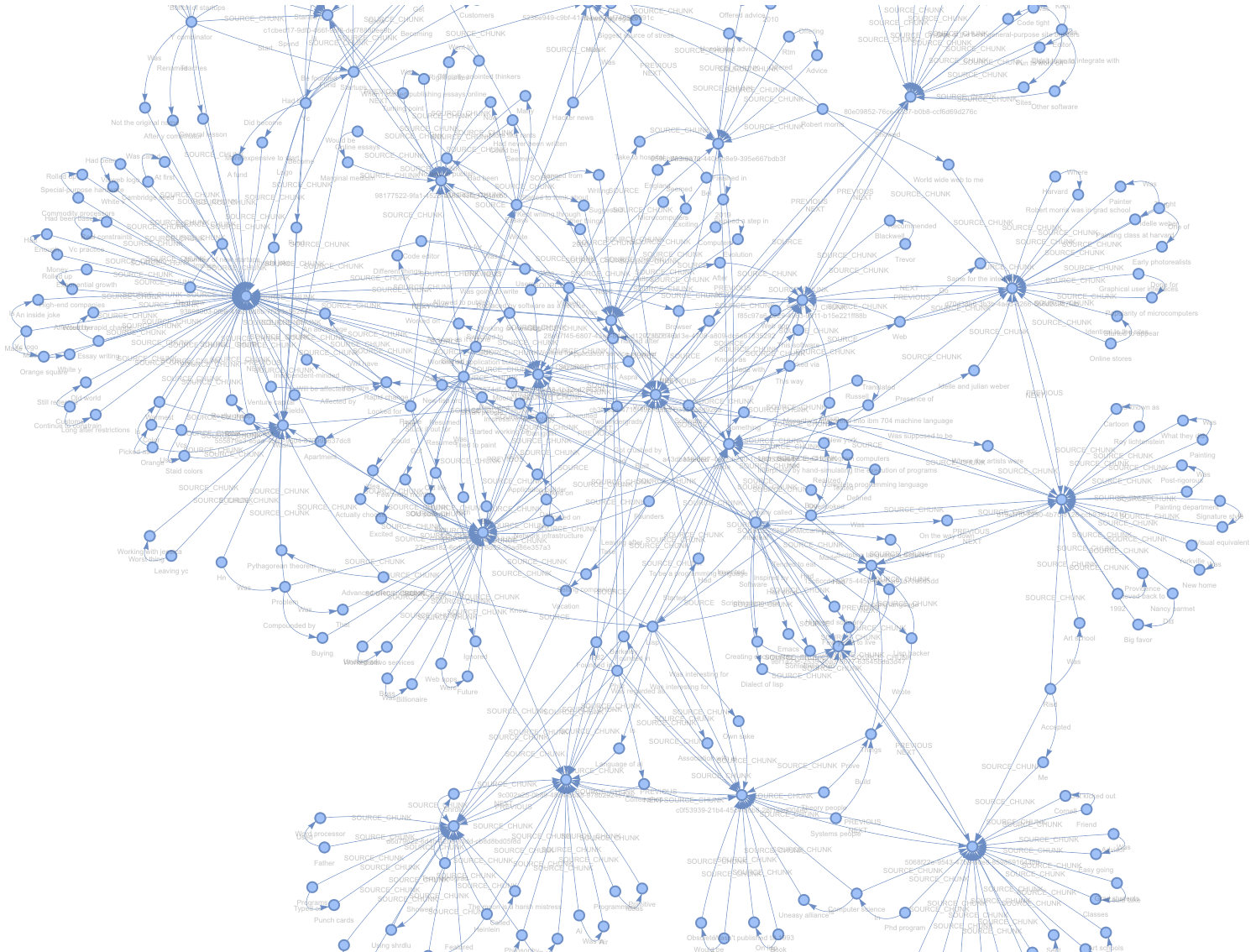
自定义底层构建¶
如果需要,我们可以使用底层 API 实现同样的数据摄取流程,利用 kg_extractors 工具。
In [ ]:
Copied!
from llama_index.core.indices.property_graph import (
ImplicitPathExtractor,
SimpleLLMPathExtractor,
)
index = PropertyGraphIndex.from_documents(
documents,
embed_model=OpenAIEmbedding(model_name="text-embedding-3-small"),
kg_extractors=[
ImplicitPathExtractor(),
SimpleLLMPathExtractor(
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.3),
num_workers=4,
max_paths_per_chunk=10,
),
],
show_progress=True,
)
from llama_index.core.indices.property_graph import (
ImplicitPathExtractor,
SimpleLLMPathExtractor,
)
index = PropertyGraphIndex.from_documents(
documents,
embed_model=OpenAIEmbedding(model_name="text-embedding-3-small"),
kg_extractors=[
ImplicitPathExtractor(),
SimpleLLMPathExtractor(
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.3),
num_workers=4,
max_paths_per_chunk=10,
),
],
show_progress=True,
)
有关所有提取器的完整指南,请参阅详细使用页面。
查询¶
查询属性图索引通常包含使用一个或多个子检索器并合并结果的过程。
图检索可以被理解为:
- 选择节点
- 从这些节点开始遍历
默认情况下,系统会同时使用两种检索方式:
- 同义词/关键词扩展 - 利用大语言模型从查询中生成同义词和关键词
- 向量检索 - 使用嵌入向量在图中查找节点
当节点被定位后,您可以:
- 返回与选定节点相邻的路径(即三元组)
- 返回路径及原始文本块内容(如果存在)
In [ ]:
Copied!
retriever = index.as_retriever(
include_text=False, # include source text, default True
)
nodes = retriever.retrieve("What happened at Interleaf and Viaweb?")
for node in nodes:
print(node.text)
retriever = index.as_retriever(
include_text=False, # include source text, default True
)
nodes = retriever.retrieve("What happened at Interleaf and Viaweb?")
for node in nodes:
print(node.text)
Interleaf -> Was -> On the way down Viaweb -> Had -> Code editor Interleaf -> Built -> Impressive technology Interleaf -> Added -> Scripting language Interleaf -> Made -> Scripting language Viaweb -> Suggested -> Take to hospital Interleaf -> Had done -> Something bold Viaweb -> Called -> After Interleaf -> Made -> Dialect of lisp Interleaf -> Got crushed by -> Moore's law Dan giffin -> Worked for -> Viaweb Interleaf -> Had -> Smart people Interleaf -> Had -> Few years to live Interleaf -> Made -> Software Interleaf -> Made -> Software for creating documents Paul graham -> Started -> Viaweb Scripting language -> Was -> Dialect of lisp Scripting language -> Is -> Dialect of lisp Software -> Will be affected by -> Rapid change Code editor -> Was -> In viaweb Software -> Worked via -> Web Programs -> Typed on -> Punch cards Computers -> Skipped -> Step Idea -> Was clear from -> Experience Apartment -> Wasn't -> Rent-controlled
In [ ]:
Copied!
query_engine = index.as_query_engine(
include_text=True,
)
response = query_engine.query("What happened at Interleaf and Viaweb?")
print(str(response))
query_engine = index.as_query_engine(
include_text=True,
)
response = query_engine.query("What happened at Interleaf and Viaweb?")
print(str(response))
Interleaf had smart people and built impressive technology, including adding a scripting language that was a dialect of Lisp. However, despite their efforts, they were eventually impacted by Moore's Law and faced challenges. Viaweb, on the other hand, was started by Paul Graham and had a code editor where users could define their own page styles using Lisp expressions. Viaweb also suggested taking someone to the hospital and called something "After."
有关自定义检索和查询的完整详情,请参阅文档页面。
存储¶
默认情况下,系统使用我们简单的内存抽象实现进行存储——SimpleVectorStore用于嵌入向量存储,SimplePropertyGraphStore用于属性图存储。
这些存储支持磁盘读写操作。
In [ ]:
Copied!
index.storage_context.persist(persist_dir="./storage")
from llama_index.core import StorageContext, load_index_from_storage
index = load_index_from_storage(
StorageContext.from_defaults(persist_dir="./storage")
)
index.storage_context.persist(persist_dir="./storage")
from llama_index.core import StorageContext, load_index_from_storage
index = load_index_from_storage(
StorageContext.from_defaults(persist_dir="./storage")
)
向量存储¶
虽然部分图数据库支持向量功能(例如 Neo4j),但在以下场景中您仍可指定在图上叠加使用的向量存储:当底层图数据库不支持向量时,或需要覆盖默认向量实现时。
下文我们将把 ChromaVectorStore 与默认的 SimplePropertyGraphStore 结合使用。
In [ ]:
Copied!
%pip install llama-index-vector-stores-chroma
%pip install llama-index-vector-stores-chroma
In [ ]:
Copied!
from llama_index.core.graph_stores import SimplePropertyGraphStore
from llama_index.vector_stores.chroma import ChromaVectorStore
import chromadb
client = chromadb.PersistentClient("./chroma_db")
collection = client.get_or_create_collection("my_graph_vector_db")
index = PropertyGraphIndex.from_documents(
documents,
embed_model=OpenAIEmbedding(model_name="text-embedding-3-small"),
graph_store=SimplePropertyGraphStore(),
vector_store=ChromaVectorStore(collection=collection),
show_progress=True,
)
index.storage_context.persist(persist_dir="./storage")
from llama_index.core.graph_stores import SimplePropertyGraphStore
from llama_index.vector_stores.chroma import ChromaVectorStore
import chromadb
client = chromadb.PersistentClient("./chroma_db")
collection = client.get_or_create_collection("my_graph_vector_db")
index = PropertyGraphIndex.from_documents(
documents,
embed_model=OpenAIEmbedding(model_name="text-embedding-3-small"),
graph_store=SimplePropertyGraphStore(),
vector_store=ChromaVectorStore(collection=collection),
show_progress=True,
)
index.storage_context.persist(persist_dir="./storage")
然后加载:
In [ ]:
Copied!
index = PropertyGraphIndex.from_existing(
SimplePropertyGraphStore.from_persist_dir("./storage"),
vector_store=ChromaVectorStore(chroma_collection=collection),
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.3),
)
index = PropertyGraphIndex.from_existing(
SimplePropertyGraphStore.from_persist_dir("./storage"),
vector_store=ChromaVectorStore(chroma_collection=collection),
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.3),
)
这与单纯使用存储上下文的情况略有不同,但由于我们已开始混合使用多种方式,现在的语法反而更加简洁。