嵌入(Embeddings)#
概念#
在LlamaIndex中,嵌入用于通过复杂的数值表示来表征您的文档。嵌入模型接收文本输入,并返回一长串数字,这些数字用于捕捉文本的语义。这些嵌入模型经过训练以这种方式表示文本,有助于实现包括搜索在内的多种应用场景。
从高层次来看,如果用户提出一个关于狗的问题,那么该问题的嵌入向量将与涉及狗相关内容的文本高度相似。
在计算嵌入向量之间的相似度时,有多种方法可供选择(点积、余弦相似度等)。默认情况下,LlamaIndex在比较嵌入向量时使用余弦相似度。
有多种嵌入模型可供选择。默认情况下,LlamaIndex使用OpenAI的text-embedding-ada-002。我们还支持Langchain提供的所有嵌入模型参见此处,同时提供了一个易于扩展的基类用于实现自定义嵌入模型。
使用模式#
在LlamaIndex中最常见的用法是在Settings对象中指定嵌入模型,然后在向量索引中使用。嵌入模型将用于在索引构建过程中嵌入文档,以及在后续使用查询引擎时嵌入任何查询。您还可以为每个索引单独指定嵌入模型。
如果尚未安装嵌入模型:
pip install llama-index-embeddings-openai
然后:
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core import VectorStoreIndex
from llama_index.core import Settings
# 更改全局默认设置
Settings.embed_model = OpenAIEmbedding()
# 局部使用
embedding = OpenAIEmbedding().get_text_embedding("hello world")
embeddings = OpenAIEmbedding().get_text_embeddings(
["hello world", "hello world"]
)
# 按索引指定
index = VectorStoreIndex.from_documents(documents, embed_model=embed_model)
为了节省成本,您可能需要使用本地模型。
pip install llama-index-embeddings-huggingface
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5"
)
这将使用来自Hugging Face的一个性能优异且快速的默认模型。
您可以在下方找到更多使用细节和可用的自定义选项。
快速开始#
嵌入模型最常见的用法是在全局Settings对象中设置它,然后使用它构建索引和查询。输入文档将被分解为节点,嵌入模型将为每个节点生成一个嵌入向量。
默认情况下,LlamaIndex会使用text-embedding-ada-002,下面的示例手动为您设置了这一选项。
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core import Settings
# 全局默认设置
Settings.embed_model = OpenAIEmbedding()
documents = SimpleDirectoryReader("./data").load_data()
index = VectorStoreIndex.from_documents(documents)
然后,在查询时,嵌入模型将再次用于嵌入查询文本。
query_engine = index.as_query_engine()
response = query_engine.query("query string")
自定义选项#
批量大小#
默认情况下,嵌入请求以10个为一批发送到OpenAI。对于某些用户,这可能(罕见地)触发速率限制。对于需要嵌入大量文档的其他用户,这个批量大小可能太小。
# 将批量大小设置为42
embed_model = OpenAIEmbedding(embed_batch_size=42)
本地嵌入模型#
使用本地模型最简单的方式是通过llama-index-embeddings-huggingface中的HuggingFaceEmbedding:
# pip install llama-index-embeddings-huggingface
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5"
)
这将加载BAAI/bge-small-en-v1.5嵌入模型。您可以使用Hugging Face上的任何Sentence Transformers嵌入模型。
除了HuggingFaceEmbedding构造函数中可用的关键字参数外,其他关键字参数会传递给底层的SentenceTransformer实例,如backend、model_kwargs、truncate_dim、revision等。
ONNX 或 OpenVINO 优化方案#
LlamaIndex 支持通过集成 Sentence Transformers 和 Optimum 工具包,使用 ONNX 或 OpenVINO 加速本地推理。
环境准备:
pip install llama-index-embeddings-huggingface
# 可选安装项:
pip install optimum[onnxruntime-gpu] # GPU版ONNX
pip install optimum[onnxruntime] # CPU版ONNX
pip install optimum-intel[openvino] # OpenVINO
指定模型与输出路径的创建方式:
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5",
backend="onnx", # 或 "openvino"
)
若模型仓库未包含 ONNX 或 OpenVINO 格式,Optimum 将自动进行转换。各方案性能基准可参考 Sentence Transformers 文档。
如何使用优化或量化模型检查点?
嵌入模型通常提供多种 ONNX/OpenVINO 检查点,例如 sentence-transformers/all-mpnet-base-v2 包含 2个OpenVINO检查点 和 9个ONNX检查点。各选项性能详情参见 Sentence Transformers文档。 可通过model_kwargs 中的 file_name 参数加载特定检查点。例如加载 sentence-transformers/all-mpnet-base-v2 仓库中的 openvino/openvino_model_qint8_quantized.xml:
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings
quantized_model = HuggingFaceEmbedding(
model_name="sentence-transformers/all-mpnet-base-v2",
backend="openvino",
device="cpu",
model_kwargs={"file_name": "openvino/openvino_model_qint8_quantized.xml"},
)
Settings.embed_model = quantized_model
CPU设备推荐方案
如 Sentence Transformers 基准测试所示,int8量化的OpenVINO模型(openvino_model_qint8_quantized.xml)在精度损失极小的情况下性能卓越。若需完全一致的结果,基础版 backend="openvino" 或 backend="onnx" 可能是最佳选择。
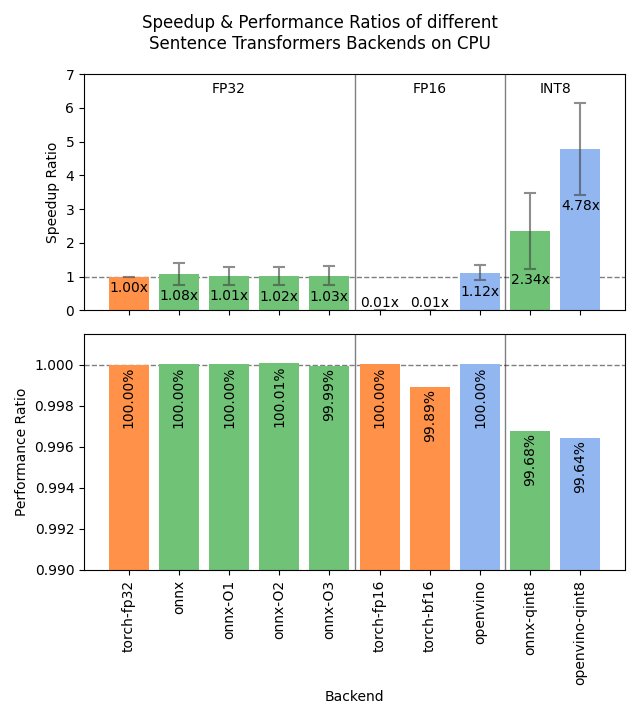 针对以下查询和文档,int8量化OpenVINO与默认Hugging Face模型的对比结果:
针对以下查询和文档,int8量化OpenVINO与默认Hugging Face模型的对比结果:
query = "哪颗行星被称为红色星球?"
documents = [
"金星因大小和位置接近地球常被称为地球的姐妹星",
"火星因其红色外观常被称为红色星球",
"木星作为太阳系最大行星拥有显著红斑",
"土星因星环系统有时被误认为红色星球",
]
HuggingFaceEmbedding(device='cpu'):
- 平均吞吐量:38.20 查询/秒(5次运行)
- 查询-文档相似度 tensor([[0.7783, 0.4654, 0.6919, 0.7010]])
HuggingFaceEmbedding(backend='openvino', device='cpu', model_kwargs={'file_name': 'openvino_model_qint8_quantized.xml'}):
- 平均吞吐量:266.08 查询/秒(5次运行)
- 查询-文档相似度 tensor([[0.7492, 0.4623, 0.6606, 0.6556]])
点击查看复现脚本
import time
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings
quantized_model = HuggingFaceEmbedding(
model_name="sentence-transformers/all-mpnet-base-v2",
backend="openvino",
device="cpu",
model_kwargs={"file_name": "openvino/openvino_model_qint8_quantized.xml"},
)
quantized_model_desc = "HuggingFaceEmbedding(backend='openvino', device='cpu', model_kwargs={'file_name': 'openvino_model_qint8_quantized.xml'})"
baseline_model = HuggingFaceEmbedding(
model_name="sentence-transformers/all-mpnet-base-v2",
device="cpu",
)
baseline_model_desc = "HuggingFaceEmbedding(device='cpu')"
query = "Which planet is known as the Red Planet?"
def bench(model, query, description):
for _ in range(3):
model.get_agg_embedding_from_queries([query] * 32)
sentences_per_second = []
for _ in range(5):
queries = [query] * 512
start_time = time.time()
model.get_agg_embedding_from_queries(queries)
sentences_per_second.append(len(queries) / (time.time() - start_time))
print(
f"{description:<120}: Avg throughput: {sum(sentences_per_second) / len(sentences_per_second):.2f} queries/sec (over 5 runs)"
)
bench(baseline_model, query, baseline_model_desc)
bench(quantized_model, query, quantized_model_desc)
# 相似度比对文档(首条为正确答案)
docs = [
"Mars, known for its reddish appearance, is often referred to as the Red Planet.",
"Venus is often called Earth's twin because of its similar size and proximity.",
"Jupiter, the largest planet in our solar system, has a prominent red spot.",
"Saturn, famous for its rings, is sometimes mistaken for the Red Planet.",
]
baseline_query_embedding = baseline_model.get_query_embedding(query)
baseline_doc_embeddings = baseline_model.get_text_embedding_batch(docs)
quantized_query_embedding = quantized_model.get_query_embedding(query)
quantized_doc_embeddings = quantized_model.get_text_embedding_batch(docs)
baseline_similarity = baseline_model._model.similarity(
baseline_query_embedding, baseline_doc_embeddings
)
print(
f"{baseline_model_desc:<120}: Query-document similarities {baseline_similarity}"
)
quantized_similarity = quantized_model._model.similarity(
quantized_query_embedding, quantized_doc_embeddings
)
print(
f"{quantized_model_desc:<120}: Query-document similarities {quantized_similarity}"
)
GPU设备推荐方案
GPU环境下OpenVINO优势不明显,ONNX性能未必优于默认torch后端的量化模型。
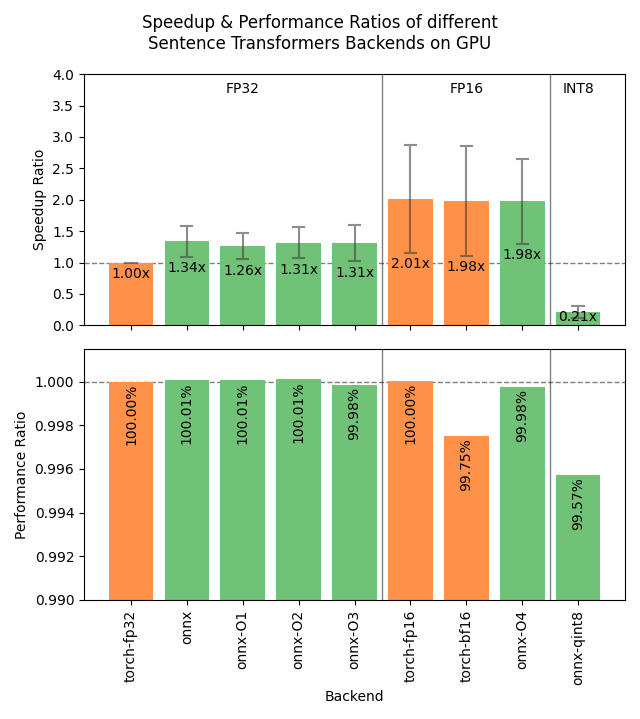 这意味着无需额外依赖即可获得显著加速,只需加载模型时指定更低精度:
这意味着无需额外依赖即可获得显著加速,只需加载模型时指定更低精度:
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5",
device="cuda",
model_kwargs={"torch_dtype": "float16"},
)
模型未提供所需后端或优化版本怎么办?
可通过Hugging Face的backend-export空间将任意Sentence Transformers模型转换为ONNX/OpenVINO格式并应用量化优化。转换后将向模型仓库提交包含新模型文件的PR。随后可通过指定revision参数使用该模型:
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5",
backend="openvino",
revision="refs/pr/16", # 对应PR:https://huggingface.co/BAAI/bge-small-en-v1.5/discussions/16
model_kwargs={"file_name": "openvino_model_qint8_quantized.xml"},
)
LangChain 集成#
我们同时支持 Langchain提供的所有嵌入模型。
以下示例通过Langchain的嵌入类加载Hugging Face模型:
pip install llama-index-embeddings-langchain
from langchain.embeddings.huggingface import HuggingFaceBgeEmbeddings
from llama_index.core import Settings
Settings.embed_model = HuggingFaceBgeEmbeddings(model_name="BAAI/bge-base-en")
自定义嵌入模型#
如需使用LlamaIndex或Langchain未提供的嵌入模型,可通过继承基础嵌入类实现自定义方案。
以下示例实现Instructor Embeddings(安装说明)的自定义类。该模型通过提供文本及其所属领域的"指令"来生成嵌入,特别适用于专业领域文本。
from typing import Any, List
from InstructorEmbedding import INSTRUCTOR
from llama_index.core.embeddings import BaseEmbedding
class InstructorEmbeddings(BaseEmbedding):
def __init__(
self,
instructor_model_name: str = "hkunlp/instructor-large",
instruction: str = "Represent the Computer Science documentation or question:",
**kwargs: Any,
) -> None:
super().__init__(**kwargs)
self._model = INSTRUCTOR(instructor_model_name)
self._instruction = instruction
def _get_query_embedding(self, query: str) -> List[float]:
embeddings = self._model.encode([[self._instruction, query]])
return embeddings[0]
def _get_text_embedding(self, text: str) -> List[float]:
embeddings = self._model.encode([[self._instruction, text]])
return embeddings[0]
def _get_text_embeddings(self, texts: List[str]) -> List[List[float]]:
embeddings = self._model.encode(
[[self._instruction, text] for text in texts]
)
return embeddings
async def _get_query_embedding(self, query: str) -> List[float]:
return self._get_query_embedding(query)
async def _get_text_embedding(self, text: str) -> List[float]:
return self._get_text_embedding(text)
独立使用#
嵌入模块也可独立用于项目开发、现有应用或测试验证:
embeddings = embed_model.get_text_embedding(
"这里正下着倾盆大雨!"
)
支持的嵌入模型列表#
我们支持与 OpenAI、Azure 以及 LangChain 提供的所有服务的集成。